Impact of Numerical Parameters¶
This notebook investigates how the reference scenario evolves if we change: - The number of correlated agents. - The number of independent agents. - The number of candidates. - The number of training samples for trained aggregators.
The common point between the four studies above is that we use the same drawings of utilities and estimates. For example, an experiment with 40 candidates will share the exact same 20 first candidates than an experiment with 20 candidates only.
First we load some packages and the dataset built in the reference scenario notebook, which contains all inputs required for the analysis presented in this notebook.
[1]:
import numpy as np
import dill as pickle
import matplotlib.pyplot as plt
from tqdm import tqdm
import tikzplotlib
from multiprocess.pool import Pool
[2]:
import embedded_voting as ev # Our own module
Direct load of some useful variables and functions.
[3]:
from embedded_voting.experiments.aggregation import make_generator, make_aggs, f_max, f_renorm
from embedded_voting.experiments.aggregation import handles, colors, evaluate, default_order
[4]:
with open('base_case_data.pkl', 'rb') as f:
data = pickle.load(f)
Correlated Agents¶
Computation¶
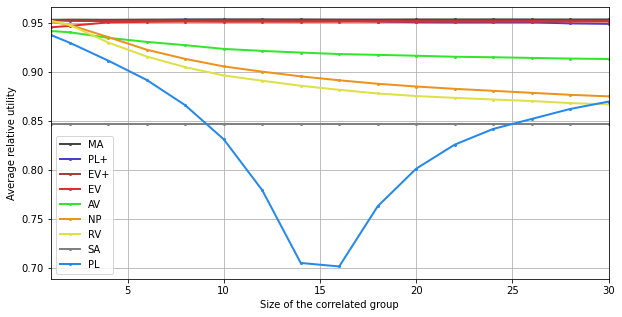
[5]:
n_c = 20
cor_size = [1] + [i for i in range(2, 31, 2)]
res = np.zeros((9,len(cor_size)))
with Pool() as p:
for j, s in enumerate(cor_size):
groups = [s] + [1]*4
voters = slice(30-groups[0], 30+len(groups)-1)
training = data['training'][voters, :]
testing = data['testing'][voters, :, :n_c]
truth = data['truth'][:, :n_c]
list_agg = make_aggs(groups)
res[:, j] = evaluate(list_agg=list_agg, truth=truth, testing=testing, training=training, pool=p)
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:11<00:00, 885.54it/s]
100%|██████████████████████████████████████████████████████████████████████████| 10000/10000 [00:08<00:00, 1202.57it/s]
100%|██████████████████████████████████████████████████████████████████████████| 10000/10000 [00:08<00:00, 1143.43it/s]
100%|██████████████████████████████████████████████████████████████████████████| 10000/10000 [00:09<00:00, 1066.39it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:10<00:00, 994.11it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:10<00:00, 957.09it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:11<00:00, 880.80it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:12<00:00, 800.92it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:12<00:00, 801.31it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:13<00:00, 764.85it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:13<00:00, 715.41it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:14<00:00, 672.15it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:15<00:00, 655.62it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:16<00:00, 613.33it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:17<00:00, 579.84it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:18<00:00, 536.30it/s]
We save the results.
[6]:
with open('correlated_agents.pkl', 'wb') as f:
pickle.dump(res, f)
Display¶
[7]:
plt.figure(figsize=(10,5))
for i, agg in enumerate(list_agg):
plt.plot(cor_size, res[i], "o-", color=colors[agg.name], label=handles[agg.name],
linewidth=2, markersize=2)
plt.legend()
plt.xlabel("Size of the correlated group")
plt.ylabel("Average relative utility")
plt.xticks(range(5,31,5), range(5,31,5))
plt.xlim(1,30)
plt.grid()
tikzplotlib.save("correlated_agents.tex", axis_height ='6cm', axis_width ='8cm')
# save figure
plt.savefig("correlated_agents.png", dpi=300)
plt.show()
Independent Agents¶
Computation¶
[8]:
ind_size = [0, 1] + [i for i in range(2, 21, 2)]
res = np.zeros((9,len(ind_size)))
[9]:
with Pool() as p:
for j, indep in enumerate(ind_size):
groups = [20] + [1]*indep
voters = slice(30-groups[0], 30+len(groups)-1)
training = data['training'][voters, :]
testing = data['testing'][voters, :, :n_c]
truth = data['truth'][:, :n_c]
list_agg = make_aggs(groups)
res[:, j] = evaluate(list_agg=list_agg, truth=truth, testing=testing, training=training, pool=p)
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:15<00:00, 663.77it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:12<00:00, 806.14it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:12<00:00, 788.17it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:13<00:00, 740.03it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:14<00:00, 685.59it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:15<00:00, 666.25it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:15<00:00, 627.06it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:16<00:00, 595.24it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:17<00:00, 558.29it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:18<00:00, 532.86it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:19<00:00, 511.57it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:20<00:00, 491.89it/s]
We save the results.
[10]:
with open('independent_agents.pkl', 'wb') as f:
pickle.dump(res, f)
Display¶
[11]:
plt.figure(figsize=(10,5))
for i, agg in enumerate(list_agg):
plt.plot(ind_size, res[i], "o-", color=colors[agg.name], label=handles[agg.name],
linewidth=2, markersize=2)
plt.legend()
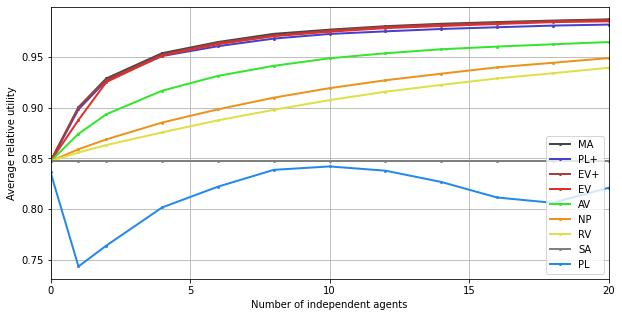
plt.xlabel("Number of independent agents")
plt.ylabel("Average relative utility")
plt.xticks(range(0,21,5), range(0,21,5))
plt.xlim(0,20)
# plt.ylim(0.5)
plt.grid()
tikzplotlib.save("independents_agents.tex", axis_height ='6cm', axis_width ='8cm')
# save figure
plt.savefig("independents_agents.png", dpi=300)
plt.show()
Candidates¶
Computation¶
[12]:
cand_size = [2,3,4,5,10,15,20,25,30,35,40,45,50]
res = np.zeros((9,len(cand_size)))
[13]:
groups = [20] + [1]*4
voters = slice(30-groups[0], 30+len(groups)-1)
with Pool() as p:
for j, n_c in enumerate(cand_size):
training = data['training'][voters, :]
testing = data['testing'][voters, :, :n_c]
truth = data['truth'][:, :n_c]
list_agg = make_aggs()
res[:, j] = evaluate(list_agg=list_agg, truth=truth, testing=testing, training=training, pool=p)
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:12<00:00, 774.52it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:10<00:00, 976.28it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:10<00:00, 960.23it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:10<00:00, 958.54it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:11<00:00, 886.43it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:12<00:00, 805.59it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:13<00:00, 740.61it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:14<00:00, 678.46it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:15<00:00, 636.49it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:18<00:00, 552.78it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:17<00:00, 556.79it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:19<00:00, 525.67it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [01:10<00:00, 141.72it/s]
We save the results.
[14]:
with open('candidates.pkl', 'wb') as f:
pickle.dump(res, f)
Display¶
[15]:
plt.figure(figsize=(10,5))
for i, agg in enumerate(list_agg):
plt.plot(cand_size, res[i], "o-", color=colors[agg.name], label=handles[agg.name],
linewidth=2, markersize=2)
plt.legend()
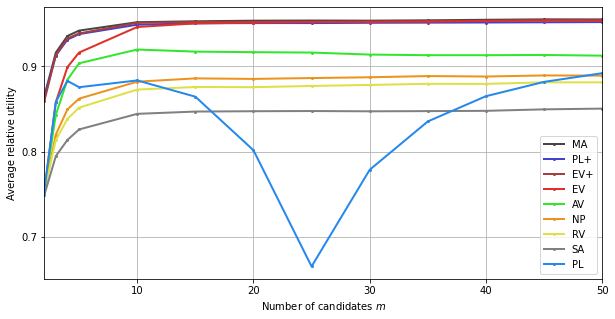
plt.xlabel("Number of candidates $m$")
plt.ylabel("Average relative utility")
plt.xticks(range(0,51,10), range(0,51,10))
plt.yticks([0.7,0.8,0.9], [0.7,0.8,0.9])
plt.xlim(2,50)
# plt.ylim(0.6)
plt.grid()
tikzplotlib.save("candidates.tex", axis_height ='6cm', axis_width ='8cm')
# save figure
plt.savefig("candidates.png", dpi=300)
plt.show()
Training Size¶
Note: due to space constraints, the following analysis, which studies the convergence speed of training for EV+ and PL+, is not reported in the paper.
Computation¶
[16]:
from copy import copy
train_size = [0,20,40,60,100,140,300,620,1260]
results = np.zeros((2,len(train_size)))
n_c = 20
for j, train in enumerate(train_size):
training = data['training'][voters, :train]
testing = data['testing'][voters, :, :n_c]
truth = data['truth'][:, :n_c]
n_tries = testing.shape[1]
list_agg = [ev.Aggregator(rule=ev.RuleRatingsHistory(rule=ev.RuleMLEGaussian(), f=f_renorm),
name="PL+"),
ev.Aggregator(rule=ev.RuleFastNash(), name="EV+")]
if training.shape[1]:
for i in range(2):
_ = list_agg[i](training).winner_
sa = groups[0]-1 # index of the last agent from the group
# We run the simulations
for index_try in tqdm(range(n_tries)):
ratings_candidates = testing[:, index_try, :]
# Welfare
welfare = ev.RuleSumRatings()(ev.Ratings([truth[index_try, :]])).welfare_
# We run the aggregators, and we look at the welfare of the winner
for k,agg in enumerate(list_agg):
agg2 = copy(agg)
w = agg2(ratings_candidates).winner_
results[k, j] += welfare[w]
res = results/n_tries
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:31<00:00, 319.79it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:32<00:00, 310.74it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:39<00:00, 250.68it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:40<00:00, 245.43it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:42<00:00, 235.20it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:51<00:00, 192.86it/s]
100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [01:11<00:00, 140.22it/s]
100%|████████████████████████████████████████████████████████████████████████████| 10000/10000 [03:10<00:00, 52.43it/s]
100%|████████████████████████████████████████████████████████████████████████████| 10000/10000 [06:01<00:00, 27.63it/s]
We save the results.
[17]:
with open('training.pkl', 'wb') as f:
pickle.dump(res, f)
Display¶
[18]:
plt.figure(figsize=(10,5))
for i, agg in enumerate(list_agg):
plt.plot([x+20 for x in train_size], res[i], "o-", color=colors[agg.name],
label=handles[agg.name], linewidth=2, markersize=2)
for i, agg in enumerate(list_agg):
plt.plot([x+20 for x in train_size], [res[i][0]]*len(train_size), "--",
color=colors[agg.name[:2]], label=handles[agg.name[:2]])
plt.legend()
plt.xlabel("Size of the training set\\\\(including candidates from the current decision)")
plt.ylabel("Average relative utility")
plt.xscale("log")
plt.xticks([x+20 for x in train_size], [x+20 for x in train_size])
plt.yticks([0.8,0.85,0.9,0.95], [0.8,0.85,0.9,0.95])
plt.xlim(20,1260)
# plt.ylim(0.5)
plt.grid()
tikzplotlib.save("training.tex")
# save figure
plt.savefig("training.png", dpi=300)
plt.show()
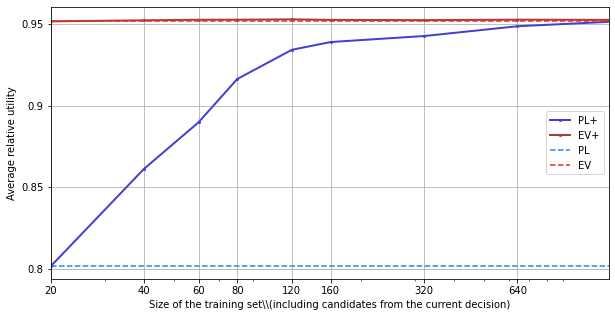
We can see that, at least in the reference scenario, EV+ doesn’t actually need to be trained. PL+ does.